Meta has published a new collection of AI models, Llama 4, in her Llama family – on a Saturday, no less.
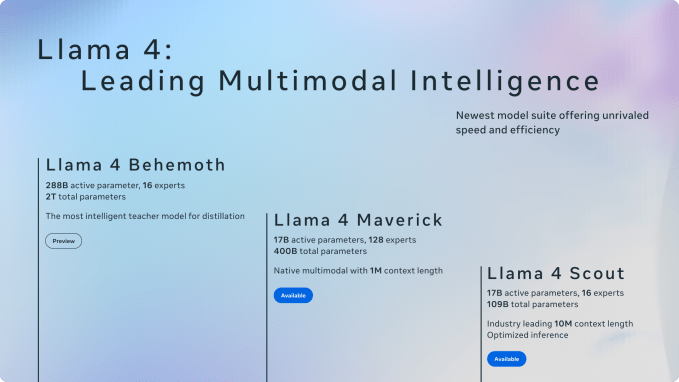
There are four new models in Total: Llama 4 Scout, Llama 4 Maverick and Llama 4 Behemoth. All were trained on “large amounts of text, image and unmarked video data” to give them a “broad visual understanding”, says Meta.
The success of the open models of the Chinese AI laboratory Deepseek, which occurs in peer or better than the previous flagship models of Meta, would have launched the development of Llama in Overdrive. Meta would have scrambled the war rooms to decipher how Deepseek lowered the cost of the race and the deployment of models like R1 and V3.
Scout and Maverick are openly available on llama.com and at Meta’s Partners, including the AI Dev Huging Face platform, while Behemoth is still in training. Meta says that Meta Ai, her assistant fueled by AI on applications, including WhatsApp, Messenger and Instagram, has been updated to use Llama 4 in 40 countries. Multimodal features are limited to the United States in English for the moment.
Some developers can contest the Llama 4 license.
Users and companies “domiciled” or with a “main activity” in the EU are prohibited from using or distributing models, probably the result of governance requirements imposed by AI and confidentiality of data from the region. (In the past, Meta has criticized these laws as too heavy.) Furthermore, as for the previous versions of Llama, companies with more than 700 million monthly active users must request a special Meta license, that Meta can grant or deny at its sole discretion.
“These Llama 4 models mark the start of a new era for the Lama ecosystem,” wrote Meta in a blog article. “This is only the start of the Llama 4 collection.”

Meta says that Llama 4 is her first cohort of models to use an expert architecture mixture (MOE), which is more efficient on the computer level for training and response to requests. MOE architectures essentially decompose data processing tasks in subtaches, then delegate them to smaller and specialized “experts” models.
Maverick, for example, has 400 billion parameters in total, but only 17 billion active Parameters through 128 “experts”. (The parameters roughly corresponds to the problem solving skills of a model.) Scout has 17 billion active parameters, 16 experts and 109 billion parameters in total.
According to meta internal tests, Maverick, which, according to the company, is the best for use cases “general assistant and cat” such as creative writing, exceeds models such as GPT-4O of Openai and Gemini 2.0 of Google on certain coding, reasoning, multilingual, small and image benchmarks. However, Maverick is not entirely measured by more competent recent models such as Google’s Gemini 2.5 Pro, Claude 3.7 of Anthropic and GPT-4.5 of Openai.
Scout forces reside in tasks such as the summary of documents and reasoning on the major code bases. Ine can have a very large context window: 10 million tokens. (The “tokens” represent pieces of raw text – for example the word “fantastic” divided into “fan”, “heaps” and “tic”.) In simple English, the scout can take images and up to millions of words, which allows him to process and work with extremely long documents.
The scout can operate on a single NVIDIA H100 GPU, while Maverick requires an NVIDIA H100 DGX or equivalent system, depending on Meta calculations.
Meta’s unpublished giant will need even more robust equipment. According to the company, Behemoth has 288 billion active parameters, 16 experts and nearly two billions of parameters in total. The internal comparative analysis of Meta a outperforming GPT-4.5, Claude 3.7 Sonnet and Gemini 2.0 Pro (but not 2.5 pro) on several assessments measuring STEM skills such as mathematical problem solving.
It should be noted that none of the LLAMA 4 models is an appropriate “reasoning” model in the direction of the O1 and O3-Mini of Openai. The reasoning models check their answers and generally answer the questions more reliable, but consequently, take more time than the traditional “unreal” models to provide answers.

Interestingly, Meta says he has set all her Llama 4 models to refuse to answer “controversial” questions less often. According to society, Llama 4 responds to political and social subjects “debated” that the previous harvest of Lama models would not do so. In addition, the company says that Llama 4 is “dramatically more balanced” with whom it invites it not to have fun.
“(Y) You can count on (Lllama 4) to provide useful factual responses without judgment,” Meta spokesperson told Techcrunch. “(W) which continues to make the Lama more reactive so that it answers more questions, can answer a variety of different points of view (…) and does not promote certain points of view compared to the others.”
These adjustments come while white house allies accuse AI chatbots of being too politically “awake”.
Many former confideurs close to President Donald Trump, including billionaire Elon Musk and the crypto and the “Tsar” David Sacks, allegedly alleged that the popular conservative opinions of censorship have censorship. Sacks has historically distinguished the Openai Chatppt as “programmed to be awake” and lie on the political subject.
In reality, the AI bias is an insoluble technical problem. The Musk IA company, XAI, had trouble creating a chatbot that does not approve of political opinions on others.
This did not prevent companies, including Openai, from adjusting their AI models to answer more questions than they would have done before, in particular questions relating to controversial subjects.
